Notes for DBMS
1.How do we select DISTINCT values from a table?
DISTINCT keyword is used to return only distinct values.Below is syntax:SELECT DISTINCT Mycolumn FROM MyTable
2.What is LIKE Operator for ?
LIKE operator is used to match patterns. A “%” sign is used to define the pattern. Below SQL statement will return all words with letter “S” SELECT * FROM Employee WHERE EmpName LIKE ‘S%’ Below SQL statement will return all words which end with letter “S” SELECT * FROM Employee WHERE EmpName LIKE ‘%S’ Below SQL statement will return all words having letter “S” in between SELECT * FROM Employee WHERE EmpName LIKE ‘%S%’
3.What is ORDER BY clause?
ORDER BY clause helps to sort the data in either ascending order to descending order. Ascending order sort query SELECT LastName FROM Employee ORDER BY EmpSalary ASC. Descending order sort query SELECT LastName FROM Employee ORDER BY EmpSalary DESC.4.What is the SQL IN Clause?
SQL IN operator is used to see if the value exists in a group of values.For instance the below SQL checks if the LastName is either ‘Shiv’ or ‘Koirala’SELECT * FROM EmployeeName WHERE LastName IN (‘Shiv’,'Koirala’) Also you can specify a not clause with the same. SELECT * FROM EmployeeName WHERE LastName NOT IN (‘Shiv’,'Koirala’)
5.Explain BETWEEN clause?
Below SQL selects employees born between ’01/01/1975′ AND ’01/01/1978′ SELECT * FROM EmployeeName WHERE DateOfBirth BETWEEN ’01/01/1975′ AND ’01/01/1978′6.You want to select the first record in a given set of rows?
Select top 1* from sales.salesperson.7.What is the default SORT order for a sql.
ASCENDING8.What is the difference between DELETE and TRUNCATE?
DELETE
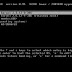
The DELETE command is used to remove rows from a table. A WHERE clause can be used to only remove some rows. If no WHERE condition is specified, all rows will be removed. After performing a DELETE operation you need to COMMIT or ROLLBACK the transaction to make the change permanent or to undo it. Note that this operation will cause all DELETE triggers on the table to fire.SQL> SELECT COUNT(*) FROM emp;
COUNT(*)
----------
14
SQL> DELETE FROM emp WHERE job = 'CLERK';
4 rows deleted.
SQL> COMMIT;
Commit complete.
SQL> SELECT COUNT(*) FROM emp;
COUNT(*)
----------
10
TRUNCATE
TRUNCATE removes all rows from a table. The operation cannot be rolled back and no triggers will be fired. As such, TRUCATE is faster and doesn’t use as much undo space as a DELETE.SQL> TRUNCATE TABLE emp;
Table truncated.
SQL> SELECT COUNT(*) FROM emp;
COUNT(*)
----------
0
DROP
The DROP command removes a table from the database. All the tables’ rows, indexes and privileges will also be removed. No DML triggers will be fired. The operation cannot be rolled back.SQL> DROP TABLE emp;
Table dropped.
SQL> SELECT * FROM emp;
SELECT * FROM emp
*
ERROR at line 1:
ORA-00942: table or view does not exist
DROP and TRUNCATE are DDL commands, whereas DELETE is a DML command. Therefore DELETE operations can be rolled back (undone), while DROP and TRUNCATE operations cannot be rolled back.
From Oracle 10g a table can be “undropped”. Example:SQL> FLASHBACK TABLE emp TO BEFORE DROP;
Flashback complete.PS: DROP and TRUNCATE are DDL commands, whereas DELETE is a DML command. As such, DELETE operations can be rolled back (undone), while DROP and TRUNCATE operations cannot be rolled back.
9.What are WILDCARD operators ?
We already have discussed SQL LIKE operator which is used to compare a value to similar values using wildcard operators. SQL supports following two wildcard operators in conjunction with the LIKE operator:| Wildcards | Description |
| The percent sign (%) | Matches one or more characters. Note that MS Access uses the asterisk (*) wildcard character instead of the percent sign (%) wildcard character. |
| The underscore (_) | Matches one character. Note that MS Access uses a question mark (?) instead of the underscore (_) to match any one character. |
The percent sign represents zero, one, or multiple characters. The underscore represents a single number or character. The symbols can be used in combinations. Syntax:The basic syntax of % and _ is as follows:
SELECT FROM table_name WHERE column LIKE 'XXXX%' or SELECT FROM table_name WHERE column LIKE '%XXXX%' or SELECT FROM table_name WHERE column LIKE 'XXXX_' or SELECT FROM table_name WHERE column LIKE '_XXXX' or SELECT FROM table_name WHERE column LIKE '_XXXX_' |
You can combine N number of conditions using AND or OR operators. Here XXXX could be any numberic or string value. Example:Here are number of examples showing WHERE part having different LIKE clause with ‘%’ and ‘_’ operators:
| Statement | Description |
| WHERE SALARY LIKE ’200%’ | Finds any values that start with 200 |
| WHERE SALARY LIKE ‘%200%’ | Finds any values that have 200 in any position |
| WHERE SALARY LIKE ‘_00%’ | Finds any values that have 00 in the second and third positions |
| WHERE SALARY LIKE ’2_%_%’ | Finds any values that start with 2 and are at least 3 characters in length |
| WHERE SALARY LIKE ‘%2′ | Finds any values that end with 2 |
| WHERE SALARY LIKE ‘_2%3′ | Finds any values that have a 2 in the second position and end with a 3 |
| WHERE SALARY LIKE ’2___3′ | Finds any values in a five-digit number that start with 2 and end with 3 |
Let us take a real example, consider CUSTOMERS table is having following records:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+ |
Following is an example which would display all the records from CUSTOMERS table where SALARY starts with 200:
SQL> SELECT * FROM CUSTOMERS WHERE SALARY LIKE '200%'; |
This would produce following result:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 3 | kaushik | 23 | Kota | 2000.00 | +----+----------+-----+-----------+----------+ |
10.What is the difference between UNION and UNION ALL ?
The SQL UNION operator combines two or more SELECT statements.The SQL UNION Operator The UNION operator is used to combine the result-set of two or more SELECT statements. Notice that each SELECT statement within the UNION must have the same number of columns. The columns must also have similar data types. Also, the columns in each SELECT statement must be in the same order. SQL UNION Syntax
| SELECT column_name(s) FROM table_name1 UNION SELECT column_name(s) FROM table_name2 |
Note: The UNION operator selects only distinct values by default. To allow duplicate values, use UNION ALL. SQL UNION ALL Syntax
| SELECT column_name(s) FROM table_name1 UNION ALL SELECT column_name(s) FROM table_name2 |
PS: The column names in the result-set of a UNION are always equal to the column names in the first SELECT statement in the UNION.
SQL UNION Example Look at the following tables: “Employees_Norway”:
| E_ID | E_Name |
| 01 | Hansen, Ola |
| 02 | Svendson, Tove |
| 03 | Svendson, Stephen |
| 04 | Pettersen, Kari |
“Employees_USA”:
| E_ID | E_Name |
| 01 | Turner, Sally |
| 02 | Kent, Clark |
| 03 | Svendson, Stephen |
| 04 | Scott, Stephen |
Now we want to list all the different employees in Norway and USA. We use the following SELECT statement:
| SELECT E_Name FROM Employees_Norway UNION SELECT E_Name FROM Employees_USA |
The result-set will look like this:
| E_Name |
| Hansen, Ola |
| Svendson, Tove |
| Svendson, Stephen |
| Pettersen, Kari |
| Turner, Sally |
| Kent, Clark |
| Scott, Stephen |
Note: This command cannot be used to list all employees in Norway and USA. In the example above we have two employees with equal names, and only one of them will be listed. The UNION command selects only distinct values.
SQL UNION ALL Example Now we want to list all employees in Norway and USA:
| SELECT E_Name FROM Employees_Norway UNION ALL SELECT E_Name FROM Employees_USA |
Result
| E_Name |
| Hansen, Ola |
| Svendson, Tove |
| Svendson, Stephen |
| Pettersen, Kari |
| Turner, Sally |
| Kent, Clark |
| Svendson, Stephen |
| Scott, Stephen |
11.What is GROUP BY clause?
Aggregate functions often need an added GROUP BY statement.The GROUP BY Statement The GROUP BY statement is used in conjunction with the aggregate functions to group the result-set by one or more columns. SQL GROUP BY Syntax
| SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name |
SQL GROUP BY ExampleWe have the following “Orders” table:
| O_Id | OrderDate | OrderPrice | Customer |
| 1 | 2008/11/12 | 1000 | Hansen |
| 2 | 2008/10/23 | 1600 | Nilsen |
| 3 | 2008/09/02 | 700 | Hansen |
| 4 | 2008/09/03 | 300 | Hansen |
| 5 | 2008/08/30 | 2000 | Jensen |
| 6 | 2008/10/04 | 100 | Nilsen |
Now we want to find the total sum (total order) of each customer. We will have to use the GROUP BY statement to group the customers. We use the following SQL statement:
| SELECT Customer,SUM(OrderPrice) FROM Orders GROUP BY Customer |
The result-set will look like this:
| Customer | SUM(OrderPrice) |
| Hansen | 2000 |
| Nilsen | 1700 |
| Jensen | 2000 |
Let’s see what happens if we omit the GROUP BY statement:
| SELECT Customer,SUM(OrderPrice) FROM Orders |
The result-set will look like this:
| Customer | SUM(OrderPrice) |
| Hansen | 5700 |
| Nilsen | 5700 |
| Hansen | 5700 |
| Hansen | 5700 |
| Jensen | 5700 |
| Nilsen | 5700 |
The result-set above is not what we wanted. Explanation of why the above SELECT statement cannot be used: The SELECT statement above has two columns specified (Customer and SUM(OrderPrice). The “SUM(OrderPrice)” returns a single value (that is the total sum of the “OrderPrice” column), while “Customer” returns 6 values (one value for each row in the “Orders” table). This will therefore not give us the correct result. However, you have seen that the GROUP BY statement solves this problem.
GROUP BY More Than One ColumnWe can also use the GROUP BY statement on more than one column, like this:
| SELECT Customer,OrderDate,SUM(OrderPrice) FROM Orders GROUP BY Customer,OrderDate |
12.What is HAVING Clause?
The HAVING ClauseThe HAVING clause was added to SQL because the WHERE keyword could not be used with aggregate functions. SQL HAVING Syntax
| SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name HAVING aggregate_function(column_name) operator value |
SQL HAVING ExampleWe have the following “Orders” table:
| O_Id | OrderDate | OrderPrice | Customer |
| 1 | 2008/11/12 | 1000 | Hansen |
| 2 | 2008/10/23 | 1600 | Nilsen |
| 3 | 2008/09/02 | 700 | Hansen |
| 4 | 2008/09/03 | 300 | Hansen |
| 5 | 2008/08/30 | 2000 | Jensen |
| 6 | 2008/10/04 | 100 | Nilsen |
Now we want to find if any of the customers have a total order of less than 2000. We use the following SQL statement:
| SELECT Customer,SUM(OrderPrice) FROM Orders GROUP BY Customer HAVING SUM(OrderPrice)<2000 |
The result-set will look like this:
| Customer | SUM(OrderPrice) |
| Nilsen | 1700 |
Now we want to find if the customers “Hansen” or “Jensen” have a total order of more than 1500. We add an ordinary WHERE clause to the SQL statement:
| SELECT Customer,SUM(OrderPrice) FROM Orders WHERE Customer=’Hansen’ OR Customer=’Jensen’ GROUP BY Customer HAVING SUM(OrderPrice)>1500 |
The result-set will look like this:
| Customer | SUM(OrderPrice) |
| Hansen | 2000 |
| Jensen | 2000 |
13.What is Primary key,Unique key,Foreign key?
Primary key - Primary key means main key def:- A primary key is one which uniquely identifies a row of a table.· It will not take any null values.
· We can use Primary Key only once in a table.
· We can declare combination of two columns as primary key.
Unique key - single and main key A unique is one which uniquely identifies a row of a table.
· If a column is declared as unique key than again there will not be any repeated value in that column.
· It will take null value.
Foreign key - a foreign key is one which will refer to a primary key of another table
for ex,
emp_table dept_table
empno empname salary deptno deptno deptname
In the above relation, deptno is there in emp_table which is a primary key of dept_table. that means, deptno is refering the dept_table.
14.What are Aggregate and Scalar Functions ?
SQL Aggregate Functions
SQL aggregate functions return a single value, calculated from values in a column.Useful aggregate functions:
· AVG() – Returns the average value
· COUNT() – Returns the number of rows
· FIRST() – Returns the first value
· LAST() – Returns the last value
· MAX() – Returns the largest value
· MIN() – Returns the smallest value
· SUM() – Returns the sum
i)SUM – The Addition Function
The SUM function returns the sum of all the values selected.
SELECT SUM(NO1) FROM NUMBERTABLE;
This will show the output:
NO1
550
To select only a few values, use the WHERE clause:
SELECT SUM(NO1) FROM NUMBERTABLE WHERE ID<6;
This will show the output:
NO1
150
You can also set the alias of the column name:
SELECT SUM(NO1) FROM NUMBERTABLE AS SUMX WHERE ID<6;
This will show the output:
SUMX
150
ii)AVG – The Average Function
The average function returns the average of all the values selected.
SELECT AVG(NO1) AS AVERAGE FROM NUMBERTABLE;
This will show the output:
NO1
55
iii)COUNT – The Count Function
The count function returns the number of all the values selected.
SELECT COUNT(NO1) AS COUNTX FROM NUMBERTABLE;
This will show the output:
COUNTX
10
iv)MAX – The Maximum Function
The MAX function returns the maximum of all the values selected.
SELECT MAX(NO1) AS XMAX FROM NUMBERTABLE;
This will show the output:
XMAX
100
v)MIN – The Minimum Function
The MIN function returns the minimum of all the values selected.
SELECT MIN(NO1) AS XMIN FROM NUMBERTABLE;
This will show the output:
XMIN
10
vi)FIRST
The FIRST function returns the first of the values selected.
SELECT FIRST(NO1) AS XFIRST FROM NUMBERTABLE;
This will show the output:
XFIRST
10
vii)LAST
The LAST function returns the last of the values selected.
SELECT LAST(NO1) AS XLAST FROM NUMBERTABLE;
This will show the output:
XLAST
100
Besides these aggregate functions, we also have scalar functions which operate on only one data value.
SQL Scalar functions
SQL scalar functions return a single value, based on the input value.Useful scalar functions:
· UCASE() – Converts a field to upper case
· LCASE() – Converts a field to lower case
· MID() – Extract characters from a text field
· LEN() – Returns the length of a text field
· ROUND() – Rounds a numeric field to the number of decimals specified
· NOW() – Returns the current system date and time
· FORMAT() – Formats how a field is to be displayed
i)UCASE Function
This function converts the text to uppercase and returns it.
SELECT LAST FROM NAME WHERE ID=1;
The output for this command yields:
LAST
aaa
SELECT UCASE(LAST) FROM NAME WHERE ID=1;
Our output is:
LAST
AAA
ii)LCASE Function
This function converts the text to uppercase and returns it.
SELECT LCASE(FIRST) FROM NAME WHERE ID=1;
Output:
FIRST
pat
iii)LEN Function
This function returns the length of the data value.
SELECT LEN(FIRST) FROM NAME WHERE ID=1;
Output:
3
iv)ROUND Function
This rounds the value of the data element and returns it.
The basic syntax is,
SELECT ROUND(DATA, NO_OF_DECIMALS) FROM TABLENAME;
For example,
SELECT ROUND(NO, 0) FROM NAME;
Output:
NO
10
20
30
40
It rounds the values 10.2 to 10, 20.4 to 20, and so forth, and then displays them.
v)MID Function
We have the following “Persons” table:
| P_Id | LastName | FirstName | Address | City |
| 1 | Hansen | Ola | Timoteivn 10 | Sandnes |
| 2 | Svendson | Tove | Borgvn 23 | Sandnes |
| 3 | Pettersen | Kari | Storgt 20 | Stavanger |
Now we want to extract the first four characters of the “City” column above.
We use the following SELECT statement:
| SELECT MID(City,1,4) as SmallCity FROM Persons |
The result-set will look like this:
| SmallCity |
| Sand |
| Sand |
| Stav |
vi)NOW Function
We have the following “Products” table:
| Prod_Id | ProductName | Unit | UnitPrice |
| 1 | Jarlsberg | 1000 g | 10.45 |
| 2 | Mascarpone | 1000 g | 32.56 |
| 3 | Gorgonzola | 1000 g | 15.67 |
Now we want to display the products and prices per today’s date.
We use the following SELECT statement:
| SELECT ProductName, UnitPrice, Now() as PerDate FROM Products |
The result-set will look like this:
| ProductName | UnitPrice | PerDate |
| Jarlsberg | 10.45 | 10/7/2008 11:25:02 AM |
| Mascarpone | 32.56 | 10/7/2008 11:25:02 AM |
| Gorgonzola | 15.67 | 10/7/2008 11:25:02 AM |
vii)FORMAT Function
We have the following “Products” table:
| Prod_Id | ProductName | Unit | UnitPrice |
| 1 | Jarlsberg | 1000 g | 10.45 |
| 2 | Mascarpone | 1000 g | 32.56 |
| 3 | Gorgonzola | 1000 g | 15.67 |
Now we want to display the products and prices per today’s date (with today’s date displayed in the following format “YYYY-MM-DD”).
We use the following SELECT statement:
|
SELECT ProductName, UnitPrice, FORMAT(Now(),’YYYY-MM-DD’) as PerDate FROM Products |
The result-set will look like this:
| ProductName | UnitPrice | PerDate |
| Jarlsberg | 10.45 | 2008-10-07 |
| Mascarpone | 32.56 | 2008-10-07 |
| Gorgonzola | 15.67 | 2008-10-07 |
15.What is SQL View ?
SQL CREATE VIEW StatementIn SQL, a view is a virtual table based on the result-set of an SQL statement.
A view contains rows and columns, just like a real table. The fields in a view are fields from one or more real tables in the database.
You can add SQL functions, WHERE, and JOIN statements to a view and present the data as if the data were coming from one single table.
SQL CREATE VIEW Syntax
|
CREATE VIEW view_name AS SELECT column_name(s) FROM table_name WHERE condition |
Note: A view always shows up-to-date data! The database engine recreates the data, using the view’s SQL statement, every time a user queries a view.
SQL CREATE VIEW Examples
If you have the Northwind database you can see that it has several views installed by default.
The view “Current Product List” lists all active products (products that are not discontinued) from the “Products” table. The view is created with the following SQL:
|
CREATE VIEW [Current Product List] AS SELECT ProductID,ProductName FROM Products WHERE Discontinued=No |
We can query the view above as follows:
| SELECT * FROM [Current Product List] |
Another view in the Northwind sample database selects every product in the “Products” table with a unit price higher than the average unit price:
|
CREATE VIEW [Products Above Average Price] AS SELECT ProductName,UnitPrice FROM Products WHERE UnitPrice>(SELECT AVG(UnitPrice) FROM Products) |
We can query the view above as follows:
| SELECT * FROM [Products Above Average Price] |
Another view in the Northwind database calculates the total sale for each category in 1997. Note that this view selects its data from another view called “Product Sales for 1997″:
|
CREATE VIEW [Category Sales For 1997] AS SELECT DISTINCT CategoryName,Sum(ProductSales) AS CategorySales FROM [Product Sales for 1997] GROUP BY CategoryName |
We can query the view above as follows:
| SELECT * FROM [Category Sales For 1997] |
We can also add a condition to the query. Now we want to see the total sale only for the category “Beverages”:
|
SELECT * FROM [Category Sales For 1997] WHERE CategoryName=’Beverages’ |
SQL Updating a View
You can update a view by using the following syntax:
SQL CREATE OR REPLACE VIEW Syntax
|
CREATE OR REPLACE VIEW view_name AS SELECT column_name(s) FROM table_name WHERE condition |
Now we want to add the “Category” column to the “Current Product List” view. We will update the view with the following SQL:
|
CREATE VIEW [Current Product List] AS SELECT ProductID,ProductName,Category FROM Products WHERE Discontinued=No |
SQL Dropping a View
You can delete a view with the DROP VIEW command.
SQL DROP VIEW Syntax
| DROP VIEW view_name |
16.What is MINUS operator?
Table Store_Information| store_name | Sales | Date |
| Los Angeles | $1500 | Jan-05-1999 |
| San Diego | $250 | Jan-07-1999 |
| Los Angeles | $300 | Jan-08-1999 |
| Boston | $700 | Jan-08-1999 |
Table Internet_Sales
| Date | Sales |
| Jan-07-1999 | $250 |
| Jan-10-1999 | $535 |
| Jan-11-1999 | $320 |
| Jan-12-1999 | $750 |
and we want to find out all the dates where there are store sales, but no internet sales. To do so, we use the following SQL statement:
SELECT Date FROM Store_Information
MINUS
SELECT Date FROM Internet_Sales
Result:
| Date |
| Jan-05-1999 |
| Jan-08-1999 |
17.What is COUNT() Function?
The COUNT function returns the number of rows in a query.The syntax for the COUNT function is:
SELECT COUNT(expression)
FROM tables
WHERE predicates;
Note:
The COUNT function will only count those records in which the field in the brackets is NOT NULL.
For example, if you have the following table called suppliers:
| Supplier_ID | Supplier_Name | State |
| 1 | IBM | CA |
| 2 | Microsoft | |
| 3 | NVIDIA |
The result for this query will return 3.
Select COUNT(Supplier_ID) from suppliers;
While the result for the next query will only return 1, since there is only one row in the suppliers table where the State field is NOT NULL.
Select COUNT(State) from suppliers;
Simple Example
For example, you might wish to know how many employees have a salary that is above $25,000 / year.
SELECT COUNT(*) as “Number of employees”
FROM employees
WHERE salary > 25000;
In this example, we’ve aliased the count(*) field as “Number of employees”. As a result, “Number of employees” will display as the field name when the result set is returned.
18.What is TRIGGER?
A database trigger is procedural code that is automatically executed in response to certain events on a particular table or view in a database.The trigger is mostly used for keeping the integrity of the information on the database. For example, when a new record (representing a new worker) is added to the employees table, new records should be created also in the tables of the taxes, vacations, and salaries.The need and the usage
Triggers are commonly used to:
· audit changes (e.g. keep a log of the users and roles involved in changes)
· enhance changes (e.g. ensure that every change to a record is time-stamped by the server’s clock)
· enforce business rules (e.g. require that every invoice have at least one line item)
· execute business rules (e.g. notify a manager every time an employee’s bank account number changes)
· replicate data (e.g. store a record of every change, to be shipped to another database later)
· enhance performance (e.g. update the account balance after every detail transaction, for faster queries)
The examples above are called Data Manipulation Language (DML)triggers because the triggers are defined as part of the Data Manipulation Language and are executed at the time the data is manipulated. Some systems also support non-data triggers, which fire in response to Data Definition Language (DDL) events such as creating tables, or runtime or and events such as logon, commit, and rollback. Such DDL triggers can be used for auditing purposes.
The following are major features of database triggers and their effects:
· triggers do not accept parameters or arguments (but may store affected-data in temporary tables)
· triggers cannot perform commit or rollback operations because they are part of the triggering SQL statement (only through autonomous transactions)
Triggers in Oracle
In addition to triggers that fire when data is modified,Oracle supports triggers that fire when schema objects (that is, tables) are modified and when user logon or logoff events occur. These trigger types are referred to as “Schema-level triggers”.
Schema-level triggers
· After Creation
· Before Alter
· After Alter
· Before Drop
· After Drop
· Before Logoff
· After Logon
The four main types of triggers are:
1. Row Level Trigger: This gets executed before or after any column value of a row changes
2. Column Level Trigger: This gets executed before or after the specified column changes
3. For Each Row Type: This trigger gets executed once for each row of the result set caused by insert/update/delete
4. For Each Statement Type: This trigger gets executed only once for the entire result set, but fires each time the statement is executed.
sample trigger for oracle->
create or replace
TRIGGER “ANSHU”.”ACCHISTORYTIGGER”
AFTER UPDATE
ON ADDACCOUNTDETAIL
REFERENCING NEW AS NEW OLD AS OLD
FOR EACH ROW
BEGIN
IF UPDATING THEN
IF(:OLD.AMMOUNT<>:NEW.AMMOUNT)THEN
INSERT INTO USER_HISTORY(HISTORY_ID,FIELDNAME,OLDVALUE,NEWVALUE,CUSTOMER_ID,HISTORY_DATE)
VALUES(SEQHISTORY.NEXTVAL,’AMMOUNT’,:OLD.AMMOUNT,:NEW.AMMOUNT,:OLD.CUSTOMER_ID,SYSDATE);
END IF;
END IF;
end ACCHISTORYTIGGER;
Mutating tables
When a single SQL statement modifies several rows of a table at once, the order of the operations is not well-defined; there is no “order by” clause on “update” statements, for example. Row-level triggers are executed as each row is modified, so the order in which trigger code is run is also not well-defined. Oracle protects the programmer from this uncertainty by preventing row-level triggers from modifying other rows in the same table – this is the “mutating table” in the error message. Side-effects on other tables are allowed, however.
One solution is to have row-level triggers place information into a temporary table indicating what further changes need to be made, and then have a statement-level trigger fire just once, at the end, to perform the requested changes and clean up the temporary table.
Because a foreign key’s referential actions are implemented via implied triggers, they are similarly restricted. This may become a problem when defining a self-referential foreign key, or a cyclical set of such constraints, or some other combination of triggers and CASCADE rules (e.g. user deletes a record from table A, CASCADE rule on table A deletes a record from table B, trigger on table B attempts to SELECT from table A, error occurs.
19.Difference Between oracle 9i and 10g?
Oracle 9i and Oracle 10g….there are more implementation differences.In terms of architecture, 9i is based on Internet technology while 10g is grid computing based one.
Many DBA features like Automated Storage Management (ASM),
Automatic Workload Repository (AWR),
Automatic Database Diagnostic Monitor (ADDM) were introduced.
ASM-it provides tools to manage file systems and volumes directly inside the database,allowing database administrators (DBAs) to control volumes and disks with familiar SQL statements in standard Oracle environments.
Thus DBAs do not need extra skills in specific file systems
or volume managers (which usually operate at the level of the operating system).
AWR-AWR (Automatic Workload Repository) is a built-in repository
that exists in every Oracle Database. At regular intervals, the Oracle Database
makes a snapshot of all of its vital statistics and workload information and stores them in the AWR.Monitoring the performance and tunning.
ADDM-ADDM (Automatic Database Diagnostic Monitor) can be describe as the database’s doctor.It allows an Oracle database to diagnose itself and determine how potential problems could be resolved.
ADDM runs automatically after each AWR statistics capture, making the performance diagnostic data readily available.
20.Stored Procedure?
Stored Procedure-In a database management system (DBMS), a stored procedure is a set of Structured Query Language (SQL) statements with an assigned name that’s stored in the database in compiled formso that it can be shared by a number of programs. The use of stored procedures can helpful in controlling access to data (end-users may enter or change data but do not write procedures), preserving data integrity (information is entered in a consistent manner), and improving productivity (statements in a stored procedure only need to be written one time).
how to write a stored procedure in oracle?
create or replace
PROCEDURE “SP_ADDPAYEE”
(
p_PAYEENAME addpayee.PAYEENAME%type,
p_ACCNO addpayee.ACCNO%type,
)
IS BEGIN
INSERT INTO addpayee( PAYEENAME, ACCNO )
VALUES ( p_PAYEENAME,p_ACCNO);
END sp_addPayee;
Difference between Procedure and Function ?
1. Function is mainly used in the case where it must return a value. Where as a procedure may or may not return a value or may return more than one value using the OUT parameter.
2. Function can be called from SQL statements where as procedure can not be called from the sql statements
3. Functions are normally used for computations where as procedures are normally used for executing business logic.
4. You can have DML (insert,update, delete) statements in a function. But, you cannot call such a function in a SQL query.
5. Function returns 1 value only. Procedure can return multiple values (max 1024).
6. Stored Procedure: supports deferred name resolution. Example while writing a stored procedure that uses table named tabl1 and tabl2 etc..but actually not exists in database is allowed only in during creation but runtime throws error Function wont support deferred name resolution.
7. Stored procedure returns always integer value by default zero. where as function return type could be scalar or table or table values
8. Stored procedure is precompiled execution plan where as functions are not.
9. A procedure may modify an object where a function can only return a value The RETURN statement immediately completes the execution of a subprogram and returns control to the caller.
21.What is Cursor
A cursor is a temporary work area created in the system memory when a SQL statement is executed. A cursor contains information on a select statement and the rows of data accessed by it.This temporary work area is used to store the data retrieved from the database, and manipulate this data. A cursor can hold more than one row, but can process only one row at a time. The set of rows the cursor holds is called the active set.There are two types of cursors in PL/SQL:
Implicit cursors:
These are created by default when DML statements like, INSERT, UPDATE, and DELETE statements are executed. They are also created when a SELECT statement that returns just one row is executed.
Explicit cursors:
They must be created when you are executing a SELECT statement that returns more than one row. Even though the cursor stores multiple records, only one record can be processed at a time, which is called as current row.
When you fetch a row the current row position moves to next row.
Both implicit and explicit cursors have the same functionality, but they differ in the way they are accessed.
22.What is constraints ?
constraints -Use a constraints to define an integrity constraint—a rule that restricts the values in a database. Oracle Database lets you create six types of constraints and lets you declare them in two ways.The six types of integrity constraint are described briefly here and more fully in “Semantics “:
1.A NOT NULL constraint prohibits a database value from being null.
2.A unique constraint prohibits multiple rows from having the same value in the same column or combination of columns but allows some values to be null.
3.A primary key constraint combines a NOT NULL constraint and a unique constraint in a single declaration.
That is, it prohibits multiple rows from having the same value in the same column or combination of columns and prohibits values from being null.
4.A foreign key constraint requires values in one table to match values in another table.
5.A check constraint requires a value in the database to comply with a specified condition.
6.A REF column by definition references an object in another object type or in a relational table. A REF constraint lets you further describe the relationship between the REF column and the object it references.
You can define constraints syntactically in two ways:
As part of the definition of an individual column or attribute. This is called inline specification.
As part of the table definition. This is called out-of-line specification.
23.What is an Index?
An index is a performance-tuning method of allowing faster retrieval of records.An index creates an entry for each value that appears in the indexed columns. By default, Oracle creates B-tree indexes.Create an Index
The syntax for creating a index is:
CREATE [UNIQUE] INDEX index_name
ON table_name (column1, column2, . column_n)
[ COMPUTE STATISTICS ];
UNIQUE indicates that the combination of values in the indexed columns must be unique.
COMPUTE STATISTICS tells Oracle to collect statistics during the creation of the index. The statistics are then used by the optimizer to choose a “plan of execution” when SQL statements are executed.
Notes for DBMS
![Notes for DBMS]() Reviewed by
Ahamed Yaseen
on
09:11
Rating:
Reviewed by
Ahamed Yaseen
on
09:11
Rating:






No comments :